日曜日は「ビジネスモデル構築のための生成AI」の研修資料の作成を進めていました。
最近は「○○のための生成AI」「生成AIによる○○」といった形で、これまでの研修・セミナー資料の更新・微調整が多いです。
そんな中で先週の相談で多かったのは、生成AIモデルへの学習させないためのオプトアウト設定に関する相談です。
生成AIでの情報漏洩のひとつにプロンプトやその結果が学習に使われ、別の問いかけの結果に使われるというものがあります。
そのためやり取りを学習に使用しないでくださいという設定がオプトアウト設定です。
これまで明示的にChatGPTを使う場合にはオプトアウトの設定をするようにセミナーでもよく話をしていました。
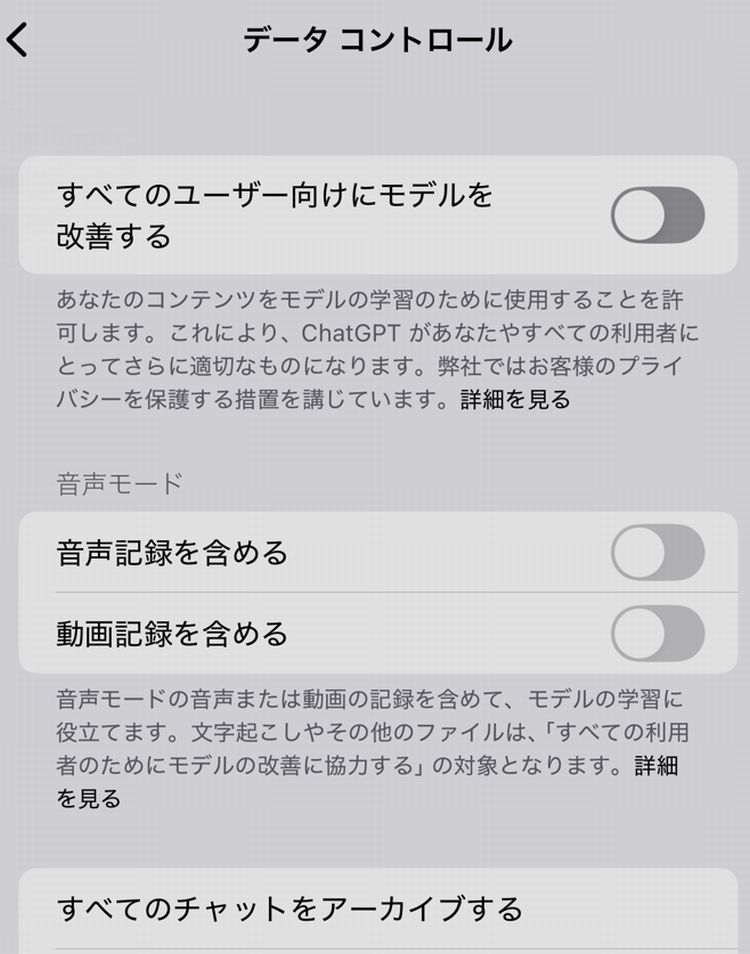
データコントロールの「全ての人のためにモデルを改善する」というところをオフにするということになります。
ただ、他のAIモデルにもオプトアウト設定があり、情報としてまとめてみました。
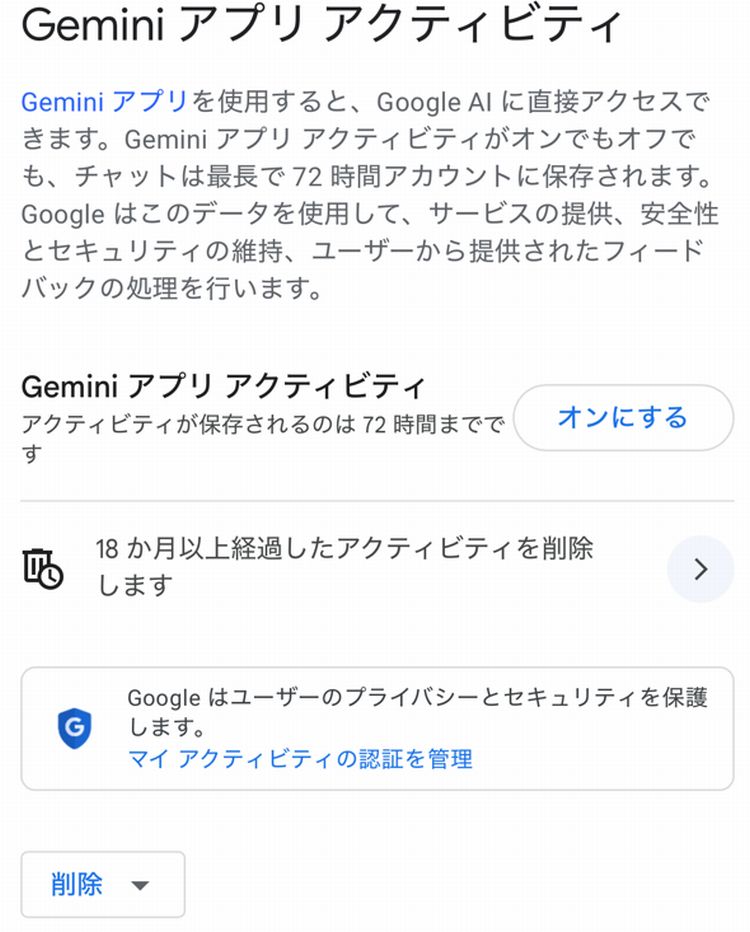
まずGeminiです。Geminiにもオプトアウトの設定らしきものがあるようです。
「Gemini アプリ アクティビティ」という設定があって、そこでアクティビティの保存を「オフ」にするような形になります。
次にClaudeです。Claudeに関しては、基本的にClaudeは学習しないがデフォルトです。
ですから、比較的安心して使えるのはClaudeなのかなという風に思いました。
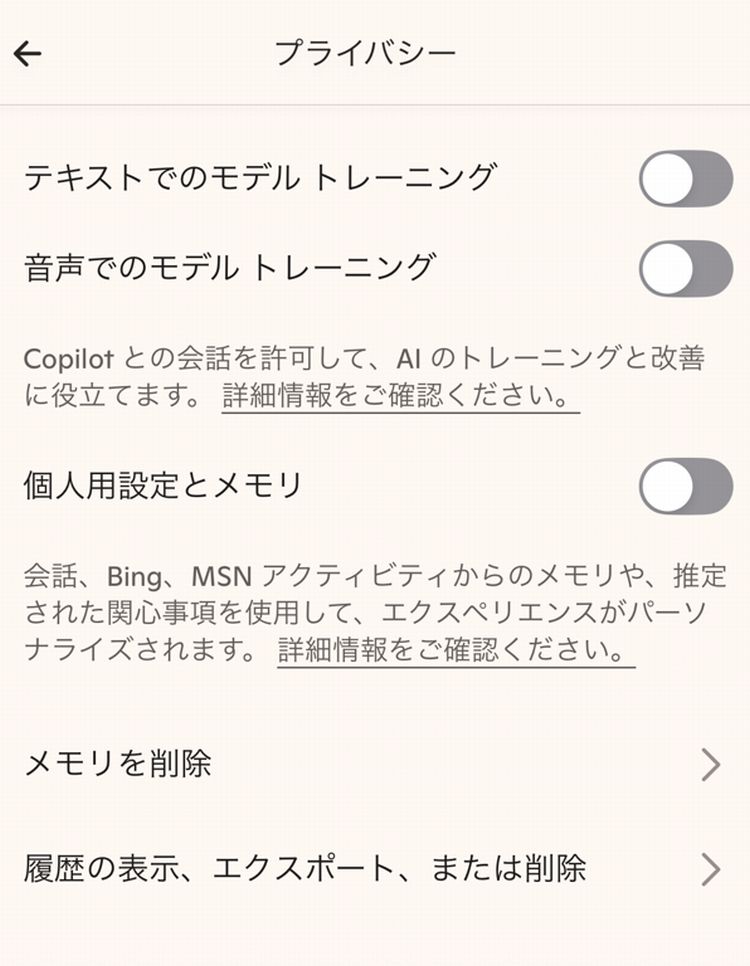
Copilot(個人用)はプライバシー設定で「テキストでのモデルトレーニング」「音声でのモデルトレーニング」を基本的にオフにしておくとよさそうです。
ちなみに組織向けCopilot for Microsoft365は、そもそも学習されないように設計されています。
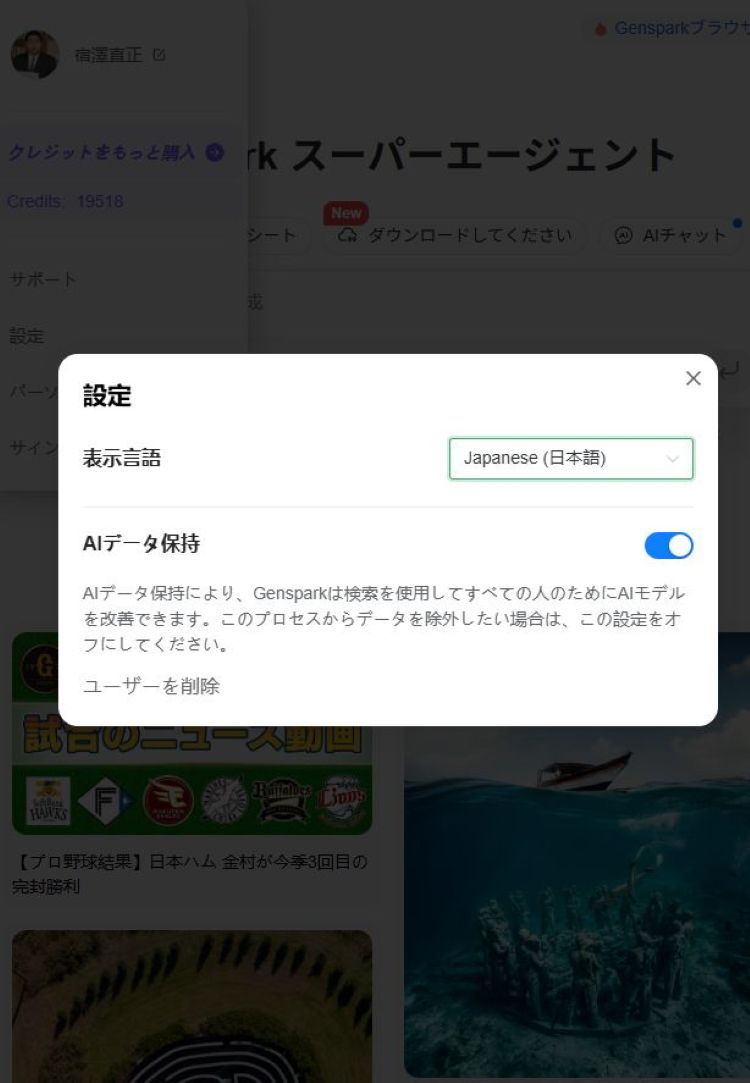
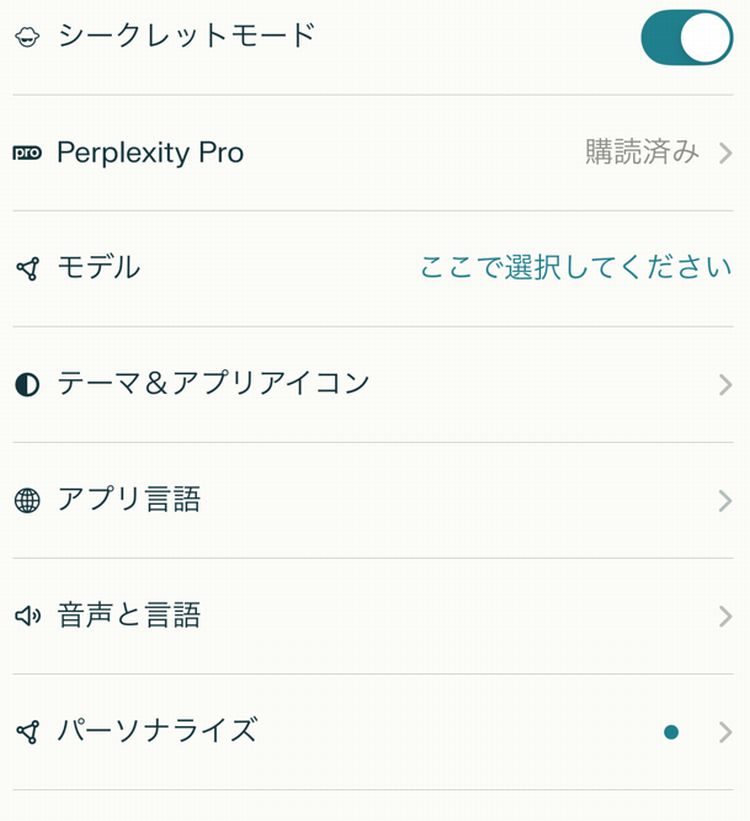
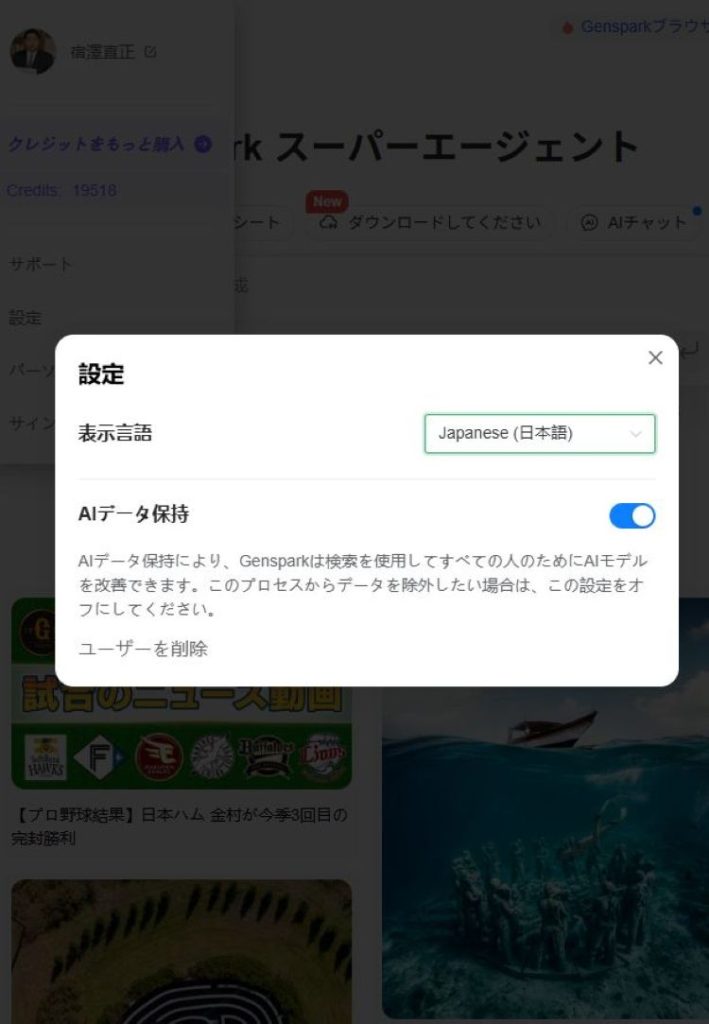
Perplexity、Felo、Genspaerkはアカウント設定から「AIデータ保持」機能を無効化します。
また、Perplexityにはシークレットモードというものがあるので、そのシークレットモードを使った方がオプトアウトされるとのことです。
ただ、基本的には生成AIにデータを入力する時に漏れてはいけない情報は入れない方がよいと思います。
Gemini for Workspace(有料版)、ChatGPTのTeamプランのようなセキュリティを重視しているようなプランを契約を検討するのもありだと思います。
生成AIの活用が本格化している中で、セキュリティや著作権に関する部分は気をつけないといけないところです。
実際の業務で生成AIを活用する際は、各サービスのオプトアウト設定を確認し、機密情報の取り扱いには十分注意を払いながら進めていくことが重要です。


