GW明けのITトレンドの勉強会&セミナーの資料を最終調整をしていました。
どちらも1時間と時間が短いので、時間配分に四苦八苦していました(毎度のことですが…)。
前のブログでは生成系AIの相談が増えていると書きましたが、その中でも画像生成AIの相談がジワリジワリと増えています
今回の勉強会&セミナーでは、話す時間が足りなくて泣く泣く見送った部分です。
画像生成AIは一気に実用的な利用シーンが増えていますが、ビジネス活用が分かりにくい一面もあります。
自分の場合はコラムやパワポにイメージ画像を挿入するレベルですが、「選ぶ」から「創る」に移行したのはワクワクします。
「StableDiffusion」「Midjourney」「Dall E-2」などの画像生成AIサービスは、その精度をどんどん上げています。
一方でお手軽な「CanvaのText to Image」や、「bingのImage Creator」などのサービスも増えています。
ただ、自分のイメージに合った画像を「創る」時の問い掛けるメッセージ(プロンプト)の難易度は、ChatGPTなどの「質問」より癖があると感じています。
それは作りたい画像を伝える際の伝え方が「理論」ではなく「感覚」だからだと思います。
画像生成の場合は「感覚」を、質問という言語へ「理論」的に変換をしないといけない難しさがあるわけです。
その現状での打開策の一つとして「イメージ(感覚)からプロンプトを知る」という方法があります。
例えば「unprompt.ai」では、自分の欲しい画像をアップして、その類似画像を提示してもらい、自分の感覚で近い画像の「プロンプト」を知ることが出来ます。
その画像の「プロンプト」を知り、それに微調整をかけることで、自分の欲しい画像の「プロンプト」を作っていきます。
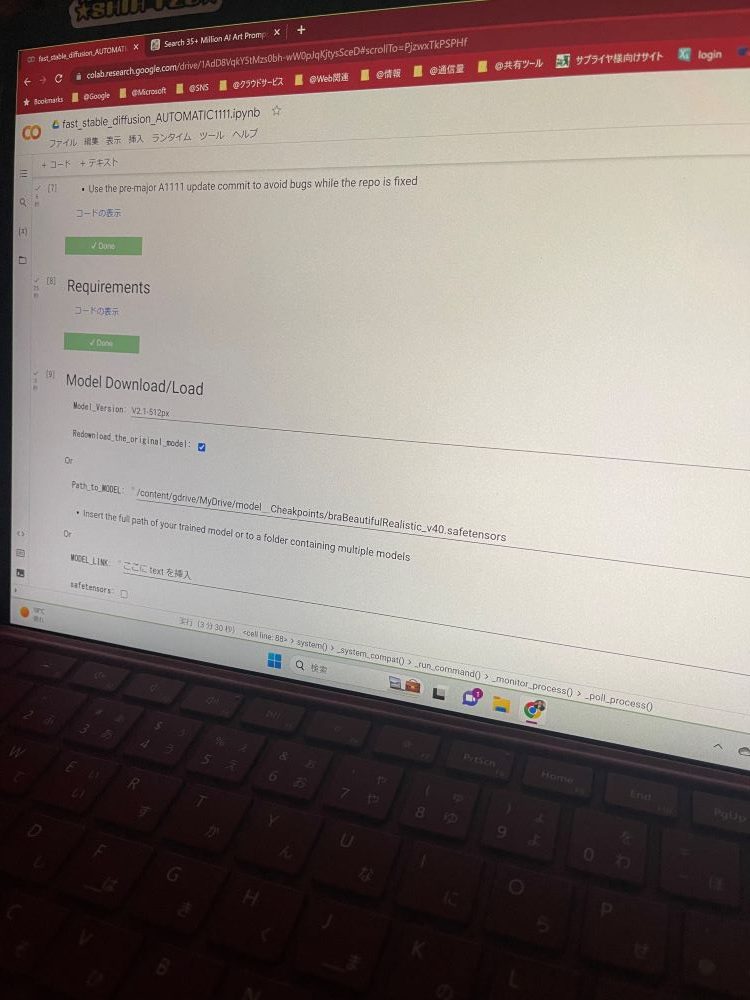
また、オープンソースの「StableDiffusion」のいくつかのモデルをGoogleColabで実行してみましたが、そのリアルな感じに驚いています。
この方法は少しややこしいので、まずはお手軽な「Canva」や「bing」で、直感的なプロンプトで試すとよいと思います。
画像生成AIは、HP、ブログ、動画、SNS、プレゼン、パンフなど…活用場面は無限だと思います。
著作権の問題など課題や議論すべきことは多いですが、画像生成AIはやり始めるとのめり込んでしまいます…。
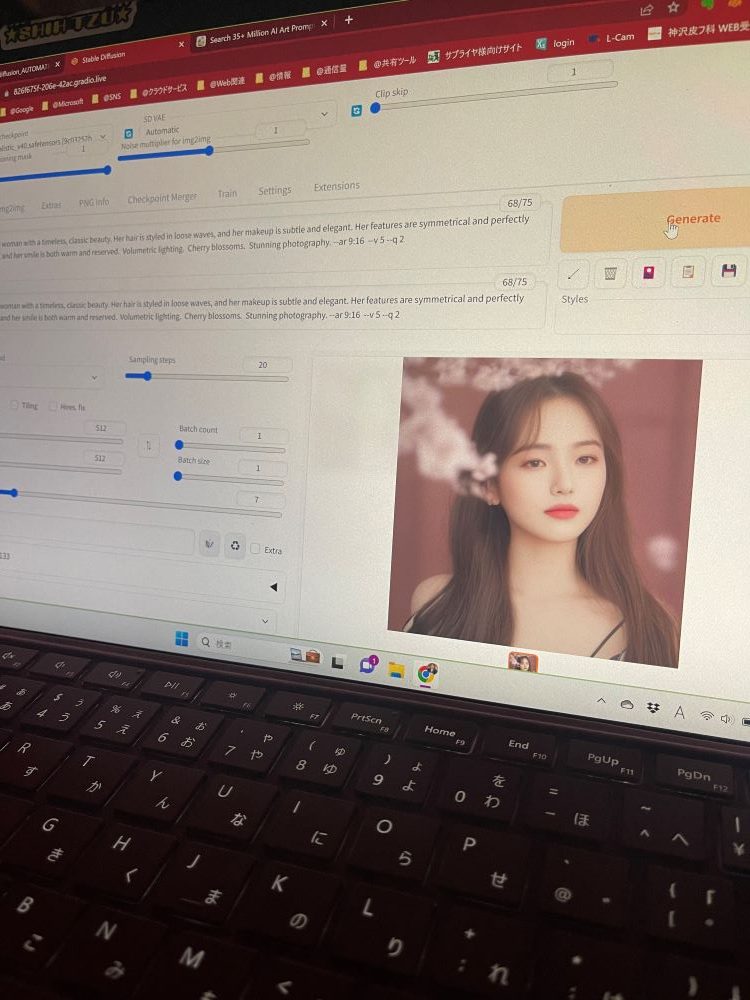
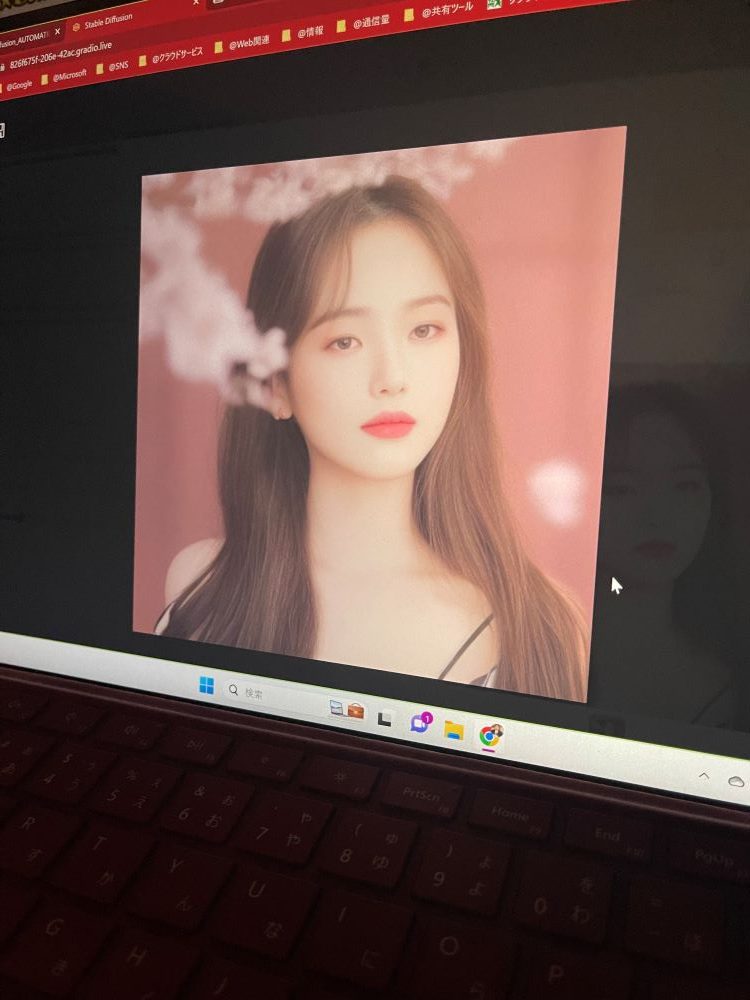
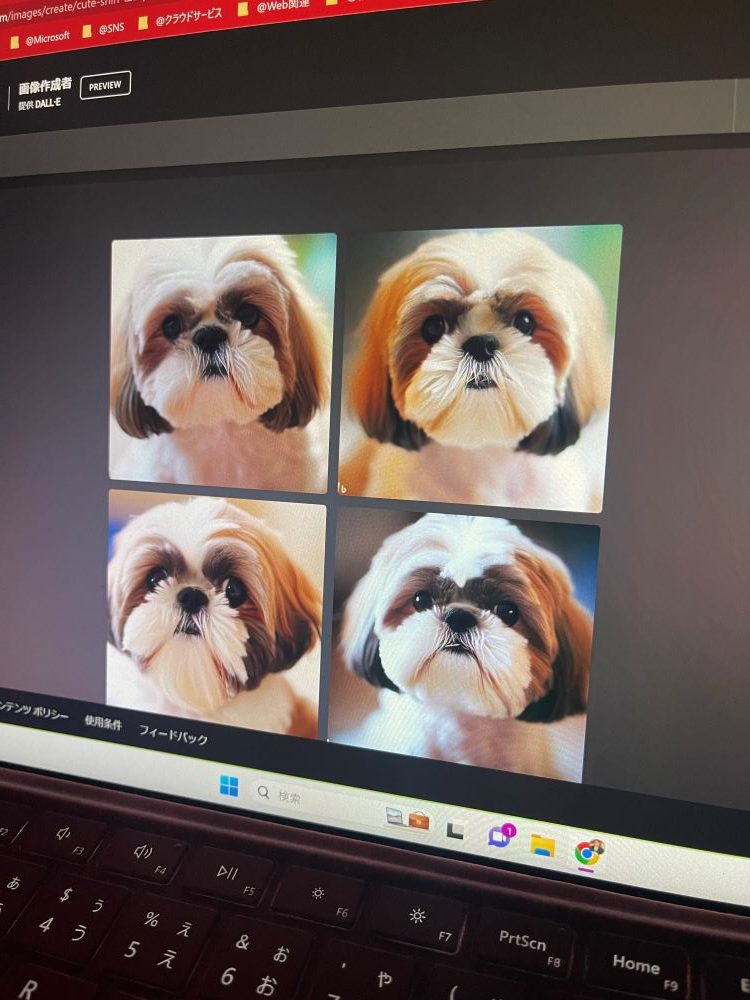
写真からお判りになると思いますが、なんとなくAIに生成させる題材が危ない方向にいっている気がします…。
理由はパオパオを生成したかったのですが、どれだけ試してもパオパオよりかわいいシーズーはAIから生まれてこなかったです。